UPDATE: Now AWS offers a "T2 Unlimited" option, which solves this limitation - read more about it here!
Some time ago, iuvo decided to move all of its resources into the cloud. Most of our resources were pretty idle and didn't need lots of CPU and memory. We had experience with Amazon Web Services, but we also looked at others such as Microsoft's Azure. After creating spreadsheets and examining resource requirements and costs, we decided to go with Amazon Web Services Elastic Compute Cloud (EC2), with most of our infrastructure on the relatively new "t2" instances.
The "t2" instances provided effective cost vs. performance characteristics. CPU performance allowed for bursts of full speed CPU usage for short times, where otherwise the system would remain idle. Excellent for our mainly internal resources that were more I/O than CPU, such as code repositories, web sites, etc. The way they worked is that you earn "CPU Credits" over time, and you accumulated them when your CPU utilization percentage was below a given "baseline" for the particular instance size. If you went above the baseline, you then consumed the credits. If you exhausted the credits, your CPU performance then was throttled until you could earn more. This is a key point - if you get into a state where your CPU performance gets throttled, then whatever is consuming all that CPU time gets less execution time, which makes it take even longer to run to completion - if it ever does.
Another key point is that there is a limit to the number of CPU credits you can earn for a given instance - the credits expire after 24 hours. This will become important later in our tale.
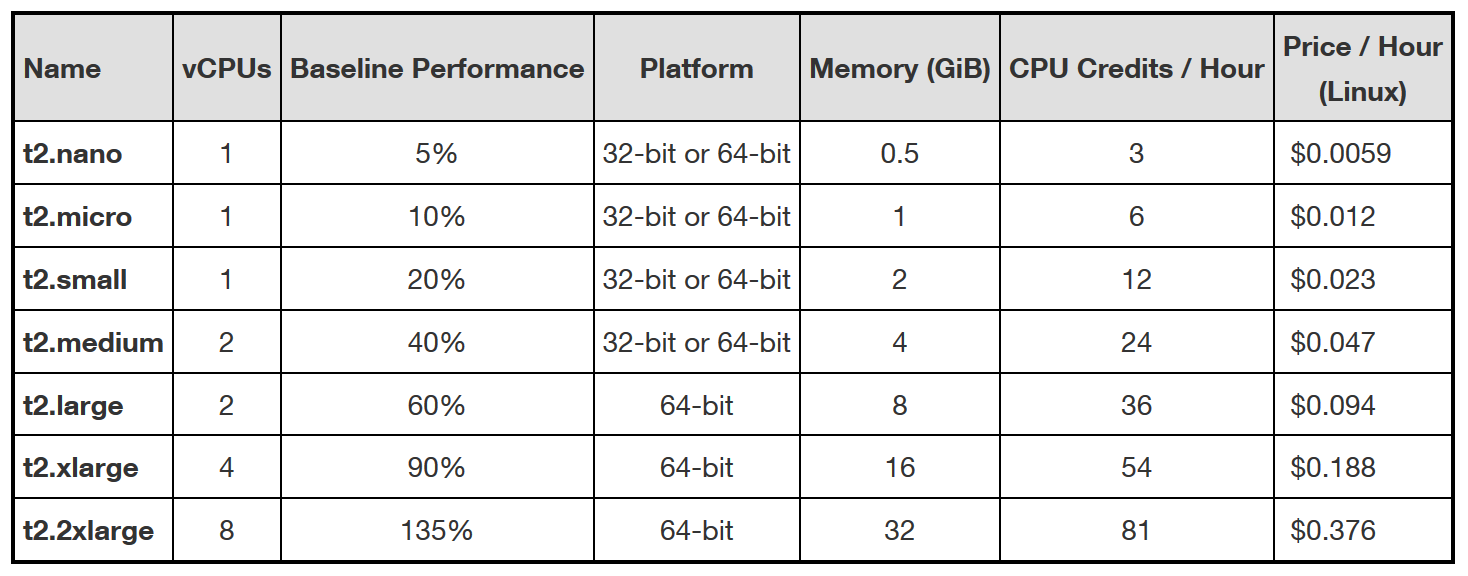
Our most CPU-intensive system was our central monitoring system. Still, it was mostly I/O-based, as most of the time was spent waiting for other systems to respond to SNMP requests, HTTP checks, etc. We measured it, and it typically ran about 18-20% aggregate CPU consumption on a virtual machine with two virtual CPUs, and rarely peaked above that. It seemed a good match for a t2.medium instance, which AWS advertised as having a 40% baseline performance, 4GB of memory and 2 vCPUs. No problem. We migrated everything and all was well.
After running fine for a while, we needed to update some custom code on the monitoring server. We utilize the AMQP message queue protocol in order to farm out monitoring checks to remote devices, and we needed to replace one of the underlying libraries in order to take advantage of some features in an update of the protocol. This also necessitated moving from a typical procedural model to an event-driven model in our code. This apparently resulted in us increasing the CPU load to close to 25% average. Still, shouldn't have been a problem.
About a day later, our monitoring system collapsed. Suddenly, most of the checks were timing out, and the number of checks attempting to run simultaneously rose. Checks were backing up in the scheduler, creating a snowball effect - once it started backing up, they got slower, which caused them the back up more, which made them slower…lather, rinse, repeat. Eventually the checks would time out, sending a mass of false alerts. Once the system decided a service was down, it would back off on the checks and reschedule, and the alerts would clear - only to fail again a few minutes later.
We tracked it down to the performance of the instance - we exhausted our CPU credits and were being throttled to 20% CPU usage, when we needed 25%. But we were expecting that baseline of 40%. So what happened? Well, it was misunderstanding their chart of baseline performance for "t2" instances. The advertised chart, which showed 2 vCPUs and 40% baseline, meant the 40% was aggregate for the two vCPUs - that is, 20% of each vCPU. But all the tools reported the CPU utilization as the average of all vCPUs - so while the graph would show us 25% utilization, it meant EACH vCPU was using 25%, and the aggregate was 50% - we were over baseline by 10% and burning our CPU credits. This makes the baseline of "135%" for a t2.2xlarge more sensible, since you couldn't exceed a 100% average performance. Amazon has since clarified on the chart, noting that the 40% of a t2.medium instance is "out of 200% max" with an annotation as to what they mean.
We have since migrated to a "c4" instance which was more expensive, but didn't have these CPU limitations. Migrating an instance between sizes is pretty easy, essentially only requiring a reboot.
More recently I ran into another "t2" limitation. I had a client that had some EC2 instances and lots of Elastic Block Storage (EBS) volumes for a project. The always-running instances were mostly idle, so "t2" instances made sense. The space needs kept growing, and we needed to consolidate several EBS volumes into one larger one. We did the migration on a t2.large instance (2 vCPUs, 60% baseline), and while it is mainly an I/O-bound operation, it does consume CPU at 40-45% CPU average during the copy against a 30% baseline. No problem, as we were using 4-4.5 CPU credits every 5 minutes, while earning 3…and we had about 800 credits to spare. Not a problem, or so we thought.
Remember that I said CPU credits expire in 24 hours? We had 800 CPU credits, and consuming only at most 1.5 credits more than we earned per 5 minute interval, or 18 per hour. We were moving a lot of data, and when we checked the next day, everything slowed down a bit. We noticed we were throttled back to 30% CPU usage because the credits were all gone! Credits are used "newest first" in a sense - so as our workload exceeded baseline for over 24 hours and we were consuming anything we earned at the time PLUS some of our backlog, all the previously earned credits expired and we were left with none. Our estimated time for the migration was exceeded.
To sum up, just beware of the limitations of the "t2" instances before jumping for the cheap price. Know what CPU performance needs you have, and how they will be affected when you exceed your limits.
{kind=link}