
by Bryon D Beilman
Our company monitors and manages high traffic web sites for our customers. It also involves using performance and log data to determine what is being accessed, by whom and perhaps why. We try to help our customers determine what is legitimate traffic, if it drives revenue or is it the basis of some type of attack. There are layers of devices from firewalls, IDS , load balancers and application level filters that can be and are fine tuned to make sure that legitimate traffic is let through and that the back end servers can successfully deliver the desired content.
As a basis, we look at where traffic comes from, what content they are viewing, byte counts and their user agent. For those who aren't familiar with User Agents, they are programs that work on behalf of the user. For web browsing, it generally helps define what browser you are coming from, so that the web site, can perhaps determine how to properly render the page. One example would be to know if you are coming from a computer or a mobile phone so that it can properly present the site and if required give you a bandwidth reduced image on the phone so that it comes up quicker.
For the context of this discussion, the other user agents that people may care about are bots. Some bots are bad and are the basis of Distributed DDOS attacks, while others are useful to make sure that people know your site is out there. Google, Yahoo and Microsoft are all making big money by indexing all of the content of the world, and using proprietary algorithms to determine how popular or useful a site is (how many people link to it). Because they want people to know they are legitimate, they usually define their user agents well, and make sure their IPs have proper DNS names so you know where they come from. They even name their search servers names like "rate-limited-proxy-72-14-199-243.google.com" so you know they are trying to be considerate when crawling your site.
Examples of typical useful clients you may see crawling your site:
crawl-66-249-71-164.googlebot.com rate-limited-proxy-72-14-199-243.google.com b3090774.crawl.yahoo.net msnbot-65-52-104-88.search.msn.comExamples of user agents you may find crawling your site:
Mozilla/5.0(compatible;bingbot/2.0;+http://www.bing.com/bingbot.htm) Mozilla/5.0(compatible;Googlebot/2.1;+http://www.google.com/bot.html) Mozilla/5.0(compatible;Yahoo! Slurp;http://help.yahoo.com/help/us/ysearch/slurp)So what does this have to do with Amazon?
Today we got an alert that there was significant traffic on a few of the sites. Initially it looked like a DDOS attack, but what I haven't seen before was that they all came from <nodename>.compute-1.amazonaws.com , 90 different ones and they all had the user agent "EC2LinkFinder". 10-30 Hits per client/minute. Now, it still looks like a DDOS attack and that's how we treated it. Notice that the user agent isn't nice like the others, where it reports it comes from Yahoo and it has a URL to learn more. This "EC2LinkFinder" was crawling the site (in parallel) and wasn't behaving nice, so it's not allowed to play with us anymore. (see below).
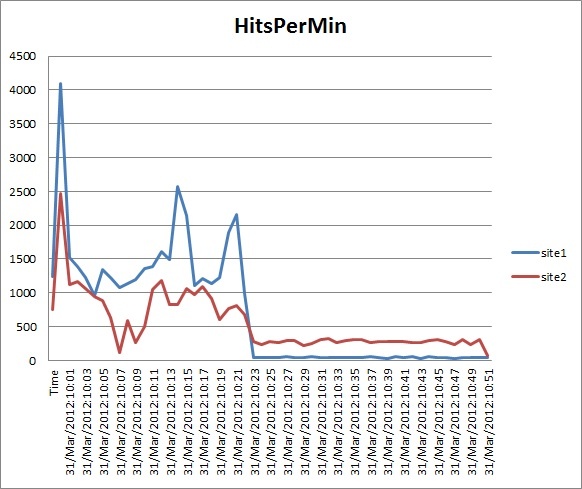
What if, however, this is really Amazon , working out their early general web search engine, using their own significant AWS infrastructure and storing the results in their S3 storage? Perhaps they haven't fine tuned their schedules and search jobs to be site friendly and haven't made their user agent name friendly because they haven't publicly announced they are doing it yet. Amazon instances get hacked all the time, so if it hadn't had the "Ec2LinkFinder" user agent, I might not have wandered down this thought path. It is well known that Google , Amazon and Facebook are all competing for our eyes and dollars. I wouldn't be surprised to find that Amazon will soon be in the search business and that this agent is part of it.
.png)

.png)