
.png)
Running large language models on your local computer can be a safe and cost-effective way to use the latest artificial intelligence tools. This blog post will outline the steps needed for local AI use on Apple Macs with Apple Silicon CPUs.
.png?width=400&height=400&name=Website%20Pictures%20(25).png)
Large Language Models
The past few years have seen an explosion in the use of generative artificial intelligence tools (AI). Initially with tools that could create and manipulate images, and then with large language models (LLMs) that can generate text. The release of OpenAI’s Chat GPT first based on the GPT 3.5 and later GPT 4.0 LLM is maybe the biggest change to computing in more than ten years. Microsoft, as a major investor in OpenAI, quickly brought the power of GPT 4.0 to Bing, at the time of this blog (early 2024) they further integrated it into many products under the copilot branding. Google has also released their Bard / Gemini chat tool as a front end to their AI tools.
The work being done with these tools is amazing, and people are using them in creative and innovative ways. However, they also present a few potential challenges. Many are starting to think they are expensive for the service provided, and the potential security concerns are even greater than the cost issues. A solution to both the cost and potential security / privacy issues is running an LLM locally on your own computer.
Wait, what!? AI requires giant server farms, with many thousands of expensive GPUs using enough electricity to power a small town. For creating the LLM, the prior sentence is often true for training an AI model. After the model is trained, using the model, called inference, requires vastly less computing resources. Most Apple Macs with Apple Silicon CPUs, gaming PCs with NVIDIA GPUs and select AMD GPUs can do AI inference today (and light training).
Speaking of these AI models, what models should be used? This is a complicated question, as there are MANY publicly available models today. OpenAI, however, has not released any models as of this writing, and when we started writing this post, neither had Google. As an example of how quickly this space is moving, Google has now released Gemma for local use as well! For this blog post we will focus on Meta’s LLAMA 2 model as it is a good general purpose LLM.
Ollama
In this blog post we will look at running a local AI model on an Apple MacBook Air (2022 model with an M2), and future posts will look at both Windows and Linux.
Local AI is a fast-moving area of computing today, there are multiple ways of running LLMs locally. This blog post will look at using Ollama which is available for free and supports many different LLMs.
Installation Steps
1. Ollama can be downloaded here.
2. Once it is downloaded, you can click on it and the program will be extracted from the zip archive. At that point, drag the Ollama application into the Applications folder.
3. Once it is in the Applications folder, Ollama can be run like any other Mac application, by clicking on it.
4. When the application is launched, what happens is nothing, at least not much. There is now an Ollama icon in the taskbar.

Actually, a lot has happened. We now have the Ollama framework and API up and ready to use.
5. We will start simply and load the Meta LLAMA2 model. Unfortunately, this will require use of the command line, but it isn’t hard. Using the built in Macintosh Terminal Application will handle everything we need to, but we also like using the iTerm2 software if using the command line often.
Using Ollama
Getting started is as simple as:
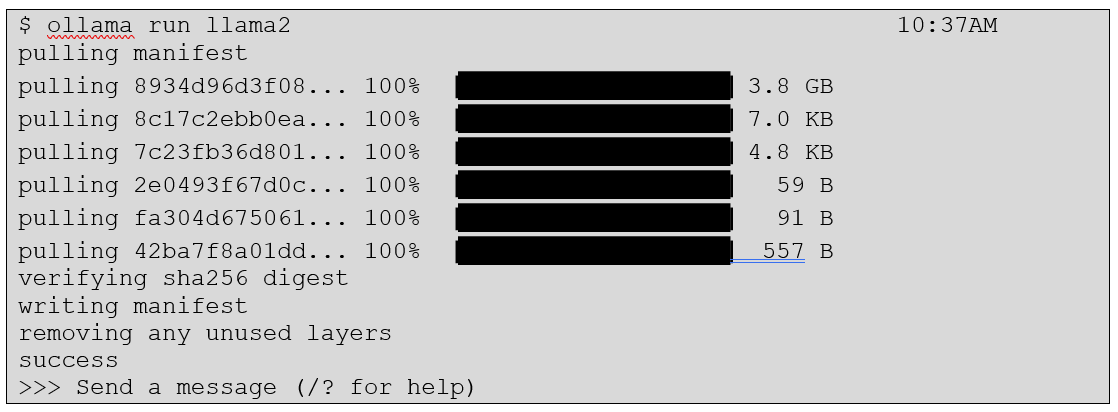
We are now ready to use our local AI!! Let's start with a fun question:

There are MANY ways to integrate Ollama into other applications, or build applications with Ollama, or setup both GUI and web front ends to Ollama. We will look at one application, Ollamac, which can be downloaded from here.
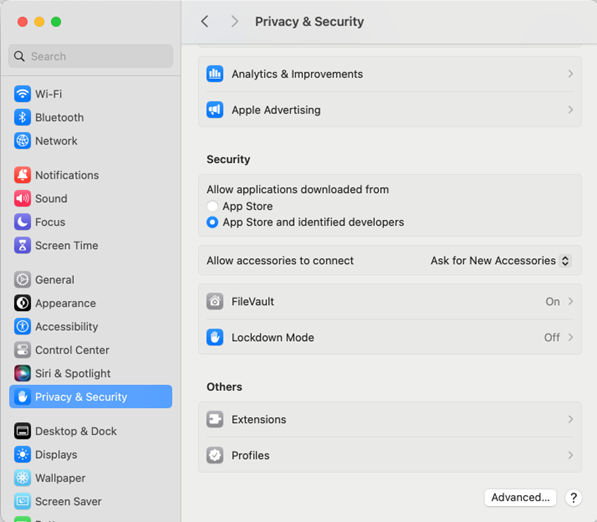
After download, it will need to be allowed access to open in System Settings – Privacy and Security:
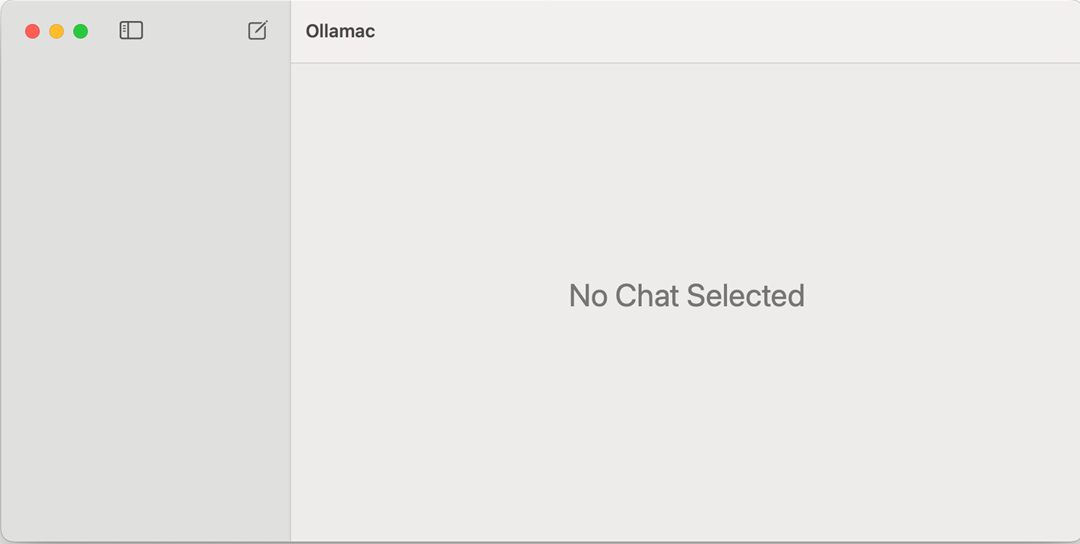
Then, drag it into Applications normally. When it is run, a GUI will look like:
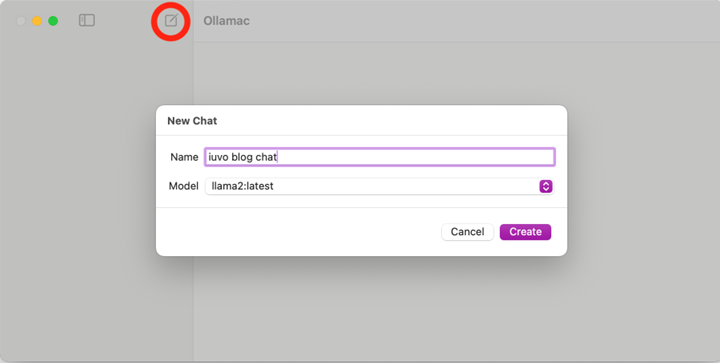
Create a new chat, and select the llama2:latest model:
Now the local AI is available in a safe, affordable and easy to use environment.
Summary
The AI space is moving at an almost incomprehensible rate. What we outlined above with Ollama is just barely scratching the surface. The real benefit is when tools like this are integrated more tightly into specific workflows, to provide insights that are difficult or time consuming to handle another way.
We hope this quick overview is helpful, and if you have further questions, or would like assistance setting up an internal AI environment at your company contact our sales team. Also keep an eye out for parts 2 and 3 on Windows and Linux.
Related Content:
-
SHOULD YOU MAKE ARTIFICIAL INTELLIGENCE (AI) A PART OF YOUR TECHNOLOGY PLATFORM?
-
HOW OPENAI'S CHATGPT IS REVOLUTIONIZING THE TECHNOLOGY WORLD
.png)

.png)