
In part one of this series, we looked at running the Meta LLAMA 2 AI large language model (LLM) on Apple Silicon base computers directly. This allows a ChatGPT like AI assistant to run without an Internet connection, but much more importantly to work without sending potentially sensitive information to an untrusted, or only semi-trusted third party. We started with the Apple Mac because it is a single hardware base for all computers, and the setup is relatively straightforward. We recommend reading the beginning of part one at the link here https://blogs.iuvotech.com/local-llms-part-1-apple-macos even you don’t have a Mac for an introduction into what we are setting up.
Setting up a local LLM on Microsoft Windows, as of this writing in the middle of March 2024 has some significant differences than with Apple MacOS. In a rare change, Microsoft Windows is not the leading platform for this type of computing. It is also not even a second-tier platform, but rather it is third tier at the moment. Linux is currently first tier, with Apple as second tier. This is also a change in regards to using AI remotely, which is what the Microsoft Copilot service does. Microsoft has done an excellent job of integrating Copilot across its product lines, and it works very well. You can read more about Copilot here: https://copilot.microsoft.com/
Hardware
The challenge Microsoft is faced with is the broad support for different types of hardware. For third party, and in this case, often unpaid open-source developers are faced with is the writing code for all of the different and often incompatible hardware. Microsoft has had to deal with similar challenges in the past, a similar one related to incompatible graphics cards and video games developers having to choose what they supported. Microsoft address this with the Direct X API that provides high performance access for games to work with hardware. Microsoft has done the same with what they termed Direct ML and allows high performance computation access for AI (or other) software to work with hardware.
Developer support for DirectML to date has been limited, and the most common tool used by developers is NVIDIA’s CUDA which works great with NVIDIA hardware, but not at all with other suppliers. AMD has developed a CUDA similar toolkit called ROCM but that is mostly limited to Linux.
This is such an important, and fast-moving field of computing, it is our expectation these deficiencies will be addressed soon, but this blog will take them into account. We will look at two general classes of systems, and outline what someone can expect from using a local LLM on each class.
Dedicated NVIDIA GPU
If a computer has a dedicated NVIDIA GPU of relatively recent vintage, say three or four years old, it should be expected the computer will work well. For this blog we even tested a seven-year-old Dell XPS 15 laptop with an Intel Core i7 7700HQ CPU, an NVIDIA 1050m mobile GPU with 4 GB of vRAM, and 32 GB of system RAM. In our testing this would probably be the lowest end system that would still be usable.
If someone was looking to purchase a system, our recommendation would be any current NVIDIA GPU with a minimum of 16 GB of vRAM, and yes, we understand that recommendation means GPUs starting at around $1000, excluding the cost of the computer, and going up from there. However, while it may be difficult to justify a $1000+ video card for playing games, using it in an AI role, can actually be very cost effective, and a substantial more performant card, in the > $10,000 price range can often be easily justified as well.
CPU Only
It is also possible to use these AI models only on the CPU. If the CPU has AVX-512 support (see here for a list https://en.wikipedia.org/wiki/AVX-512#CPUs_with_AVX-512) it will still run okay with smaller models. The other requirement is 16 GB of vRAM as an absolute minimum, but more realistically 32 GB of RAM should be considered the minimum. We tested various systems, and found performance spotty, but more memory beyond 16 GB and more CPU cores always helped.
Ollama
In this blog post we will stay with using the Ollama software like in part 1, and now has preview support for Microsoft Windows, it can be downloaded here: https://ollama.com/ Ollama currently supports NVIDIA GPUs natively on Windows, and will automatically fall back to CPU support if an NVIDIA GPU is not detected. Installation is straightforward, and doesn’t require elevated user rights. Download with Windows preview and double click it in the Downloads folder. After it is installed just run it from the Start menu.
Like with the Mac, once it is running, nothing will happen.
Using Ollama
The use of Ollama is exactly the same as with a Mac, open a command prompt and run an LLM. Like in part one we will use the Meta LLAMA2 LLM.
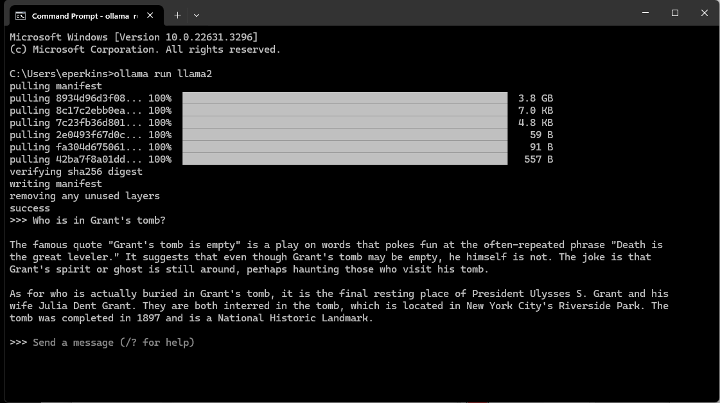
An interesting point about LLMs in general, we gave the same prompt to the same LLM in part 1, and now, and got two completely different responses.
User Interfaces
As Ollama on Microsoft Windows is very new, there is minimal support for pre-built GUIs similar to what MacOS has. We do expect that to change quickly. We will look at tying it into Microsoft Visual Studio Code. The first step is to install Microsoft Visual Studio Code application, which is available as a free download from Microsoft.
https://code.visualstudio.com/
This should be installed without elevated privileges into your user folder. Next we should install the Ollama Autocoder extension from here:
https://marketplace.visualstudio.com/items?itemName=10nates.ollama-autocoder
One setting change we made to the extension was to use LLAMA2 as the model. We do this by opening Visual Studio Code, Extensions, Ollama Autocoder, Extension Settings, and then Ollama-autocoder: Model
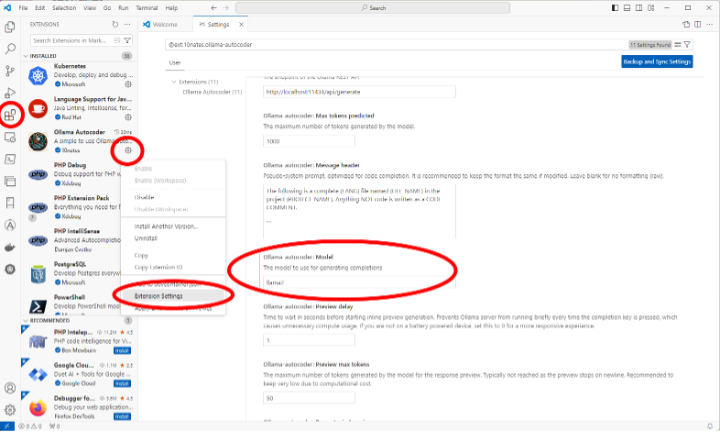
Then you can just start typing a new text document, or source code, whatever, and when you want AI assistance, press space and wait a short while and Ollama will present options for you to autocomplete what you are typing.
Summary
We have outlined implementing a local LLM on Windows. When compared to MacOS, the hardware setup is a little more difficult, and there is a little less software support. Given the market share that Microsoft Windows has, we expect both of these things to change quickly. If a computer has a relatively new NVIDIA GPU with 16 GB of RAM and the computer has a recent CPU and more than 16 GB of RAM, a local LLM will deliver good to excellent performance today.
We will look at Linux next, and in that post also show how to connect a Windows computer to the Linux host, to provide all of the benefits of a local LLM to Windows systems that don’t have the hardware capabilities to run it now.
We hope this quick overview is helpful, and if you have further questions, or would like assistance setting up an internal AI environment at your company contact our sales team. Also, keep an eye out for part 3 on Linux.
.png)

.png)