
In part I and part II of this series we looked at setting up local LLMs running on Apple MacOS and Microsoft Windows respectively. This post is going to dig into using Linux to run an LLM. In several respects Linux is different from both MacOS and Windows. Most likely, Linux will be setup as some type of server, and folks will connect to it remotely to utilize its resources. In a way, that will make this NOT a local LLM, but what we mean by it is the LLM is running on a computer directly controlled be the user or organization that is utilizing the LLM. This is also a place where running a GPU enabled public cloud instance could work well for a business, and yet still falls under the “local” we are referring to. It is also possible that a small subset of readers have Linux as their desktop, and this would also work for them, and operate similarly to what we wrote about in parts I and II.
Hardware
Like with Windows, Linux has broad support for different types of hardware. Linux is also something of the “first tier” when it comes to AI workloads. MacOS is catching up quickly but the hardware, even a fully loaded Mac Pro isn’t as powerful as dedicated Linux GPU optimized servers. Microsoft Windows can also struggle with higher end servers (large CPU core counts, large memory), and as we saw part 2 the library support isn’t mature yet.
Dedicated NVIDIA GPU
With Linux, unless the user wants to contain everything to a laptop, a dedicated GPU is a must have due to the increased performance. The range of GPUs available for Linux from NVIDIA is basically the entire product line. However, that wide choice also means it is easy to pick the wrong card. One serious problem can be going with a “server” card in a desktop, or “desktop” card in a server. This can cause catastrophic problems, as the cooling with servers and desktops is different, and the card must match the chassis cooling solution. Also, the range of cards with numbers of CUDA cores and vram is vast. If the use is just LLMs for example, purchasing an NVIDIA H100 probably doesn’t make sense. If you are looking at a dedicated Linux server for LLMs, please reach out, and we can help with the specifications to make sure everything will work properly together, and the performance will match the workload.
Dedicated AMD GPU
Unlike with Windows, on Linux AMD also has supported GPU solutions that work with LLMs (and other GPU workloads) with their ROCM software platform. Where AMD tends to be a challenger in this field the price / performance of their solutions are often favorable when compared to NVIDIA. Setting up ROCM can be a little more challenging than CUDA, but this is another area we can assist. If there are going to be multiple systems configured, the marginal setup complexity increase over NVIDIA is eliminated.
CPU Only
It is also possible to use these AI models only on the CPU, like with Windows, and it will have all the same negatives and positives that Windows has. For laptops this can be an option, but for servers we strongly recommend a GPU.
Linux Distribution
An area where Linux is very different than MacOS and Windows is that there are many distributions of Linux that have specific customizations for one task or another. There are also distributions that have completely overlapping use cases with other distributions and the difference is how Linux is setup or managed. When looking at which distribution to use, the best approach is to start with what an organization is comfortable with, and then determine if CUDA or ROCM is supported on that distribution. If this is an organization’s first use of Linux, and it is just for LLM use, we recommend the long-term support (LTS) version of Ubuntu Linux due to its popularity in the AI space and solid CUDA and ROCM support. This selection is another area we can assist in.
Ollama
In this blog post we will stay with using the Ollama software like in the two earlier posts. We are also going to assume Linux is setup with CUDA or ROCM already.
For NVIDIA CUDA installation there is a guide here:
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
For AMD ROCM installation there is a guide here:
https://rocm.docs.amd.com/projects/install-on-linux/en/latest/
We are also available to assist with getting either CUDA or ROCM setup on your Linux system. There is also a nice utility call nvtop that can monitor GPU utilization and RAM available that we recommend you install.
https://github.com/Syllo/nvtop
Once the GPU is working Ollama is installed with the command:
sudo curl -fsSL https://ollama.com/install.sh | sh
The above command will create a systemd unit start file:
/etc/systemd/system/ollama.service
At the time of this post the contents of this file are:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin"
[Install]
WantedBy=default.target
By default, Ollama will only be available to users directly logged into the system, and in many cases this should work. Another option is to allow connections to Ollama from outside the server. This presents a security risk, as Ollama doesn’t have authentication or authorization currently. Certainly, the server should not be connected to the Internet, and a local firewall that controls access by IP address should be used. We will make changes to allow access by changing the file with a few additions highlighted in red:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
WorkingDirectory=/var/lib/ollama
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin" "HOME=/var/lib/ollama" "GIN_MODE=release" "OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=multi-user.target
If external access to Ollama is desired and the above changes are made to the systemd unit file this command must be run to reread the file:
sudo systemctl daemon-reload
Also note the environment variable “OLLAMA_HOST=0.0.0.0” is telling the Ollama server to listen on ALL interfaces. Once again, we can’t stress enough this should not be on the public Internet, and even within an organization, there should be some protection for the Ollama server like a firewall that only allows specific IP addresses access to the service.
The Ollama service can then be started with:
sudo systemctl start ollama
Now we are ready to use Ollama!
Using Ollama
In a terminal we can now run Ollama the same as in the previous two blog posts:
ollama run llama2
Using our standard question from the previous posts, we will see once again a different response from the LLM.

The other item to note, when the above prompt is input, the response should return very fast, if it is possible to read the response as it is being returned the GPU isn’t working.
User Interfaces
In the prior posts we looked at different user interfaces, focusing on improving the built in CLI that Ollama comes with. In this post we are also going to look at how to share Ollama services beyond just the single Linux system it is running on.
Visual Studio Code
In part 2 we looked at using Visual Studio Code with Microsoft Windows with the Ollama-autocoder plugin. In this post we will continue to work with that plugin, running on Windows or MacOS, but connected to the Linux server. The first step is to install Microsoft Visual Studio Code application, which is available as a free download from Microsoft.
https://code.visualstudio.com/
This should be installed without elevated privileges into your user folder. Next, we should install the Ollama Autocoder extension from here:
https://marketplace.visualstudio.com/items?itemName=10nates.ollama-autocoder
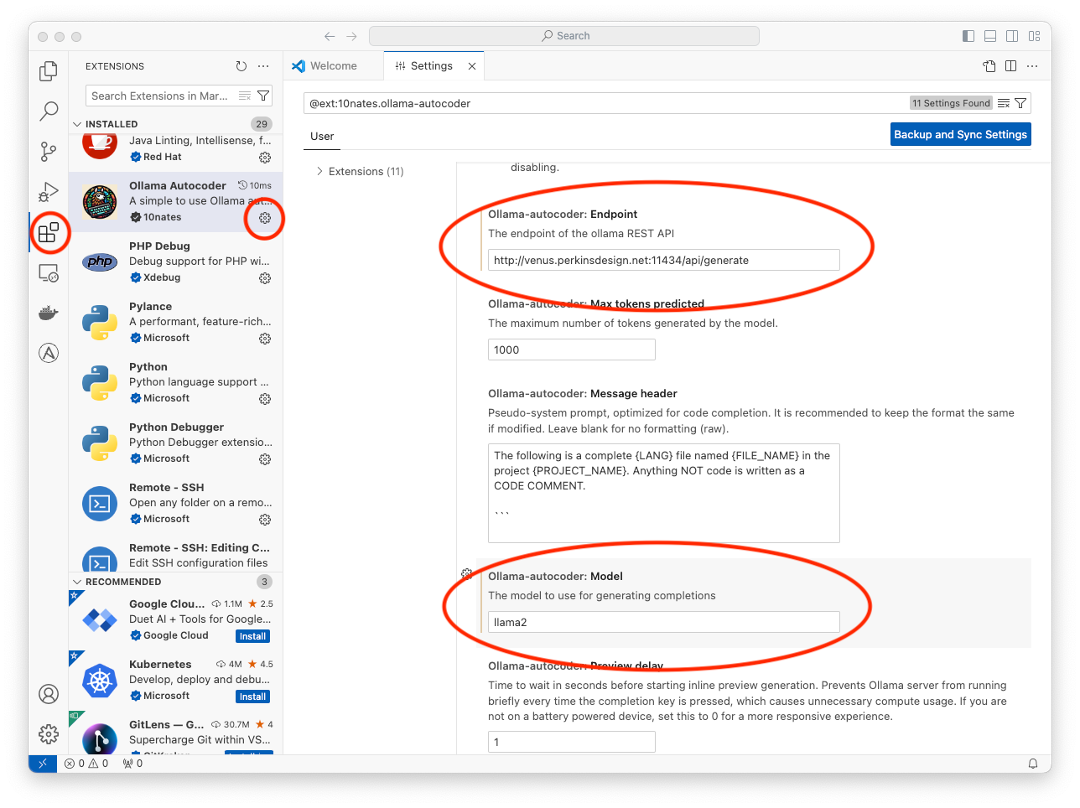
One setting change we made to the extension was to use LLAMA2 as the model. We do this by opening Visual Studio Code, Extensions, Ollama Autocoder, Extension Settings, and then we need to change two settings rather than just one in part 2:
Ollama-autocoder: Model – llama2
Ollama-autocoder: Endpoint – {hostname of your Ollama Linux Sever}:11434/api/generate
Then you can just start typing a new text document, or source code, whatever, and when you want AI assistance, press space and wait a short while and Ollama will present options for you to autocomplete what you are typing, the same as in part 2. In our testing, we found the response to be much faster using a higher end system.
Open WebUI
We are also going to look at running Open WebUI on our Linux server. More information about Open WebUI can be found at: https://openwebui.com/
We are going to run the interface in a Docker container directly on our Ollama Linux server. With Docker it is a one line command to start the container:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Once the container is started, which may take a short while the first time it is run, we can access the WebUI console at:
http://{hostname of your Ollama Linux Sever}:3000
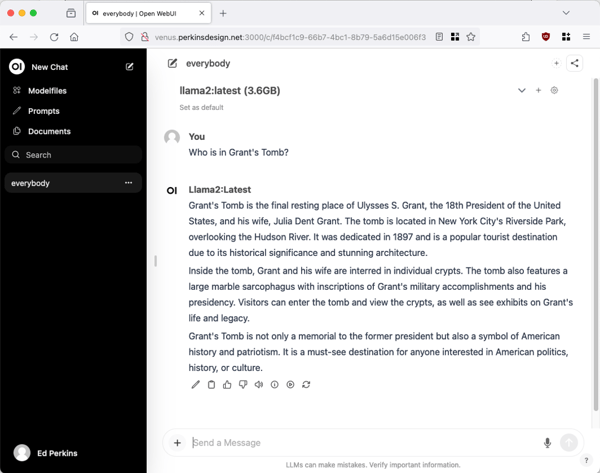
We will be presented with a login window, in small text there is an option to Sign Up, note this only creates an account within the container running on the Linux host, not on the Linux host itself, or anywhere else. Once logged in, we can select a model and start a chat session:
Summary
We now wrap up the three-part series on running local AI Large Language Models. As we started with, this is a very fast-moving field with some major announcements made while this was being written. Linux servers are excellent at supporting higher end hardware that supports LLMs at a large scale, and the software continues to improve at a rapid pace. Using Ollama with the growing number of client applications that support it presents a new type of tool, without some of the potential pitfalls of public services.
We are available to discuss all of your company’s AI needs, contact us!

.png)
